CSAPP3e-学习笔记-第六章
存储技术
随机访问存储器(RAM)
- 最基本的存储单位称为单元,一个单元存储一个 bit。
- RAM 是易失的,意味着如果断电,就会丢失 RAM 中所保存的信息。
局部性
局部性原理(Principle of Locality):程序倾向于使用最近一段时间,距离其较近地址的指令和数据。
时间局部性
当前被访问的信息近期很可能 还会被再次访问。例如,你读取了一个变量,那么你有可能会再次读取该变量。
空间局部性
在最近的将来将用到的信息很可能与现在正在使用的信息在空间地址上是临近的。
局部性的定性判断
1 | |
关于上述代码,可以发现 for 循环中的元素的访问顺序是跳跃式的,空间局部性较差,所以这个程序有着较差的局部性。
存储器层次结构
软硬件的基本稳定特性:
- 高速存储器技术成本高、容量小,且耗电大、易发热。
- CPU 与存储器之间的速度差距越来越大。
- 编写良好的程序往往表现出良好的局部性。
以上特性给出一条设计存储器系统的途径——存储器层次结构(memory hierarchy)。

高速缓存 Cache
高速缓存(Cache):
- 一种更小、速度更快的存储设备。
- 作为更大、更慢存储设备的缓存区。
存储器层次结构的基本思想:
- 对于每个 $k$,位于 $k$ 层的更快更小存储设备作为位于 $k+1$ 层的更大更慢存储设备的缓存。
为什么存储器层次结构行得通?
- 因为局部性原理,程序访问第 $k$ 层的数据比访问第 $k+1$ 层的数据要频繁。
- 因为我们不经常访问第 $k+1$ 层的数据,所以第 $k+1$ 层的存储设备可以更慢、容量更大、价格更便宜。
存储器层次结构构建了一个大容量的存储池:
- 其存储容量大小大约等于最底层存储设备的大小、同时也像底层存储器一样廉价。
- 却可以以最高层存储设备的速度来访问。
工作方式
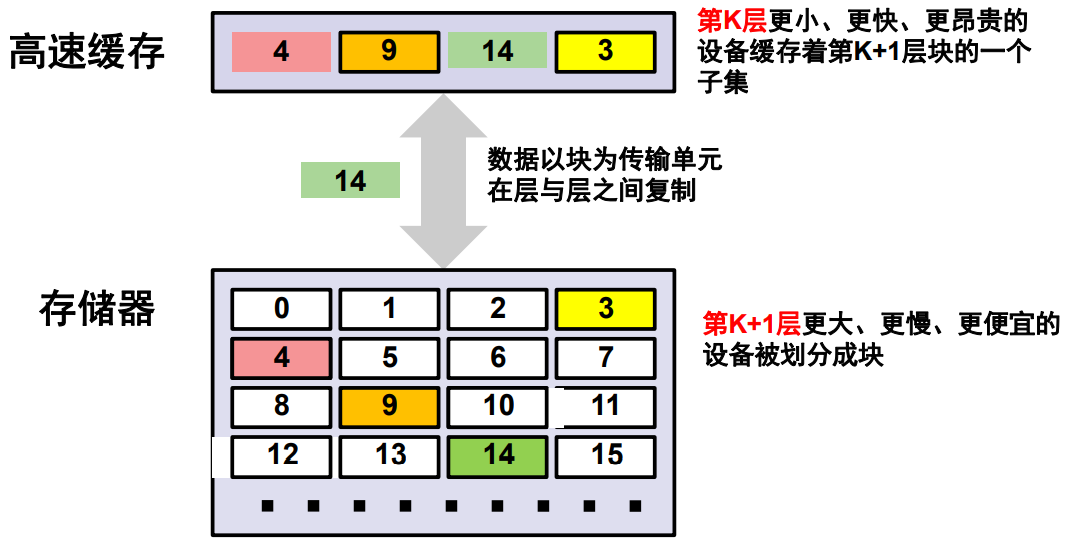
在任何时间点,高速缓存都保存主缓存器中块的一个子集。所以高速缓存的速度会更快,但是容量也更小、价格也更加的昂贵。
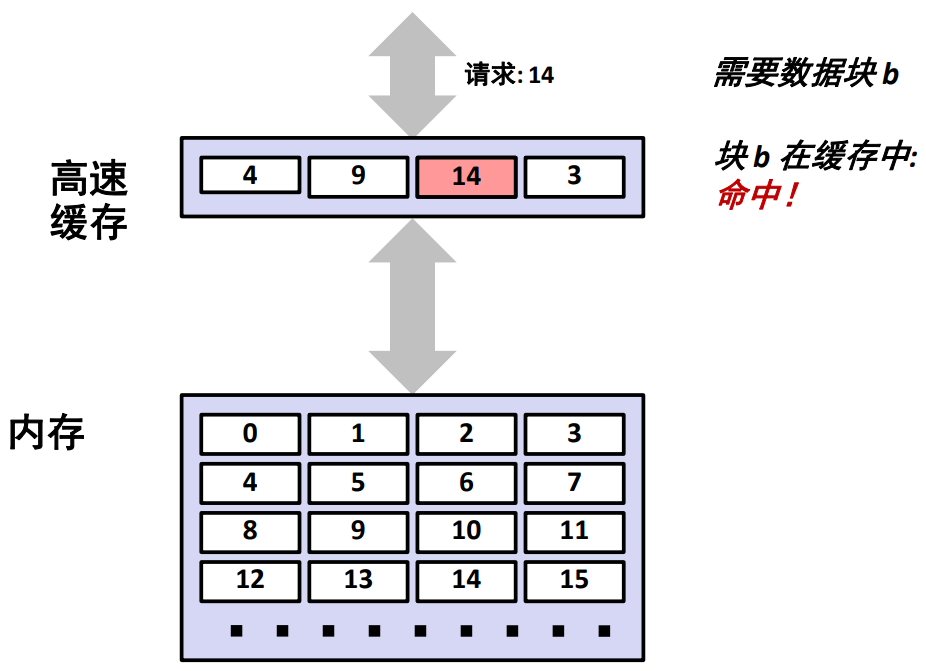
缓存命中
当 CPU 请求的数据可以直接在高速缓存中发现的话,那么就可以直接从高速缓存中取出相应的数据块并返回给 CPU。这样会使得获取数据更快。
缓存不命中
当请求的数据在高速缓存中没有发现的时候,高速缓存会先从内存中取出相应的所需要的数据,将其复制到高速缓存中,然后再从缓存中将所请求的数据返回给 CPU。所以当缓存不命中的时候会需要更长的时间。
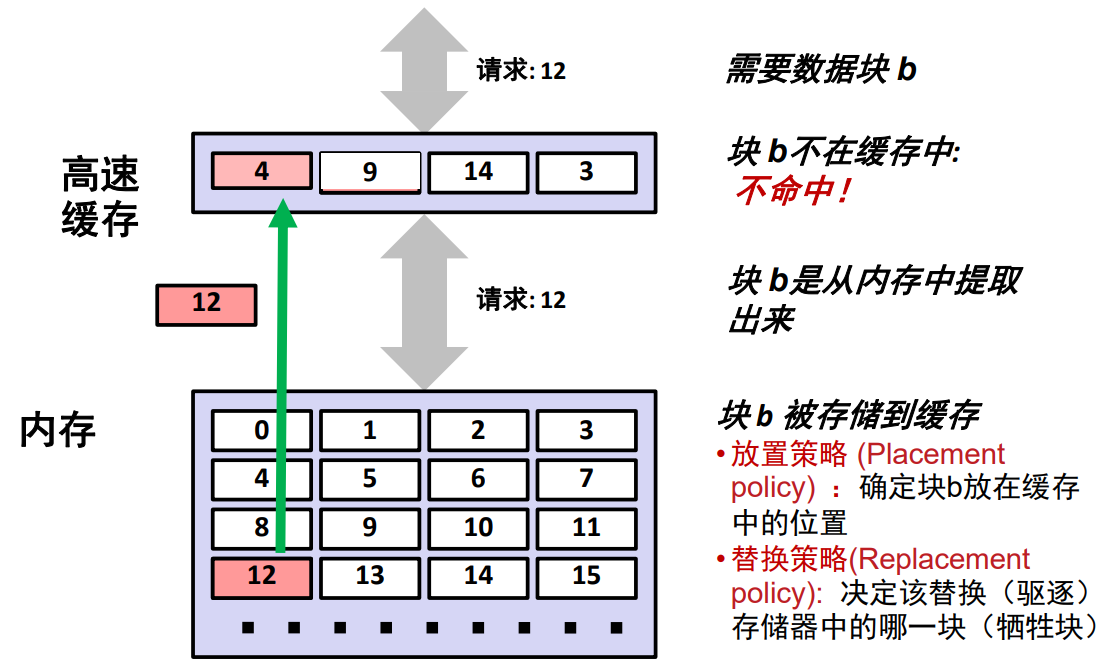
缓存不命中的种类
- 冷不命中(强制不命中)
- 最初高速缓存为空时,即没有存储任何块。对任何数据的请求都会不命中,此类不命中称为冷不命中。
- 冲突不命中
- 大多数缓存将第 $k+1$ 层的某个块限制放置在第 $k$ 层块的一个小的子集中(有时只是一个块)。
例如第 $k$ 层复制算法为 $k+1$ 层中第 $i$ 个块会复制到第 $k$ 层中第 $i \space mod\space 3$ 个位置中。那么我们不断循环请求第 0 个、第 3 个、第 6 个……块的数据时,高速缓存就会一直交替复制所请求的块到第 0 个位置,即使其他的位置都是空闲的。这就出现了冲突不命中 。 - 冲突不命中发生在缓存足够大,但是这些多个数据对象会映射到同 一个缓存块。
- 大多数缓存将第 $k+1$ 层的某个块限制放置在第 $k$ 层块的一个小的子集中(有时只是一个块)。
- 容量不命中
- 发生在当活跃块集合(工作集 working set)的大小比缓存容量大时。
例如高速缓存只能存储 4 个块,但是我们需要一次性请求 8 个块时,自然容量仅有 4 个块的高速缓存无法放下整个 8 个块的数组,便会出现容量不命中。
- 发生在当活跃块集合(工作集 working set)的大小比缓存容量大时。
高速缓存存储器 Cache Memories
高速缓存存储器(Cache Memories)是小型的、快速的基于 SRAM 的存储器,是在硬件中自动管理的(非用户程序访问的)。存储器中存储着主存储器中经常访问的块。
CPU 首先查找该高速缓存存储器中的数据,这只需要花费几个「时钟周期」。
典型的系统结构如下图所示:
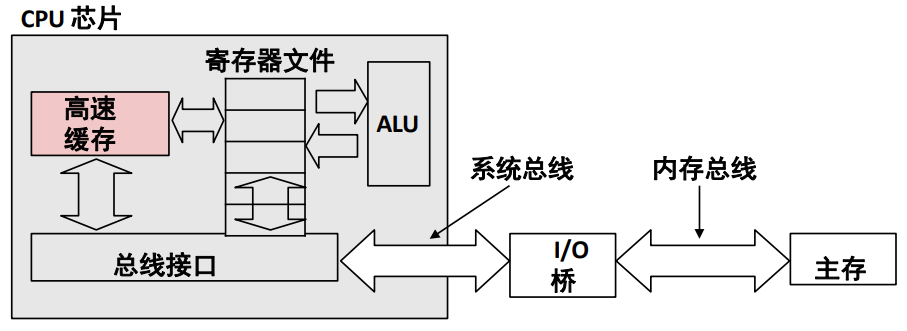
其中现代 CPU 设计如下图所示:
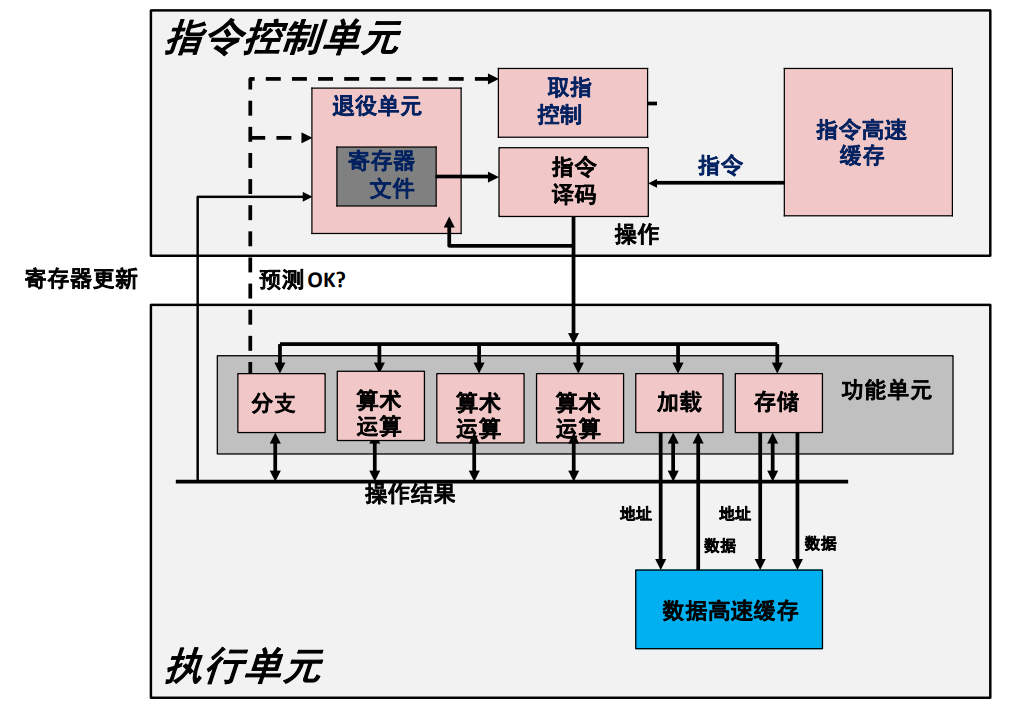
高速缓存存储器组织结构
高速缓存的基本设计思想
结构模块化:
- CPU 访问 Cache 或主存时,以字为单位。
- Cache 和主存交换信息时,以块为单位(Cache 的一块也称为一行),一次读入一块或多块内容;每块由若干个字组成。
- Cache 的每行都设置有标记,CPU 访问程序或数据时,先访问标记。
此结构全部由硬件实现。
Cache 对程序员是透明的,即程序员不必知道是否存在 Cache。
高速缓存的基本构成
存储体
基本单位为字,若干个字构成一个数据块。
地址映射变换机构
用于将主存地址变换为 Cache 地址,以利用 CPU 发送的主存地址访问 Cache。
替换机构
若要更新 Cache 中数据时使用的机制。
相联存储器
Cache 的块表,快速指示所要访问的信息是否在 Cache 中。
读写控制
主存与 Cache 的地址映射
信息从主存到 Cache 中,如何定位?
Cache 的容量小于主存,需要采用某种算法确定主存和 Cache 中块的对应关系。
地址映射
CPU 访存时,将主存地址按某种映射函数关系变换成 Cache 地址的过程。
地址映射的方式
直接映射、组相联映射、全相联映射。
高速缓存结构图
高速缓存是一个高速缓存组的数组。每个组包含 一个或多个高速缓存行,每个行包含一个有效位,一些标记位,以及一个数据块。
有效位(valid bit)指明这个行是否包含有意义的信息。有效位的长度为 1 个 bit。当 valid 等于 1 时,表示数据有效;当 valid 等于 0 时,表示数据无效。
标记位唯一地标识存储在这个高速缓存行中的块:
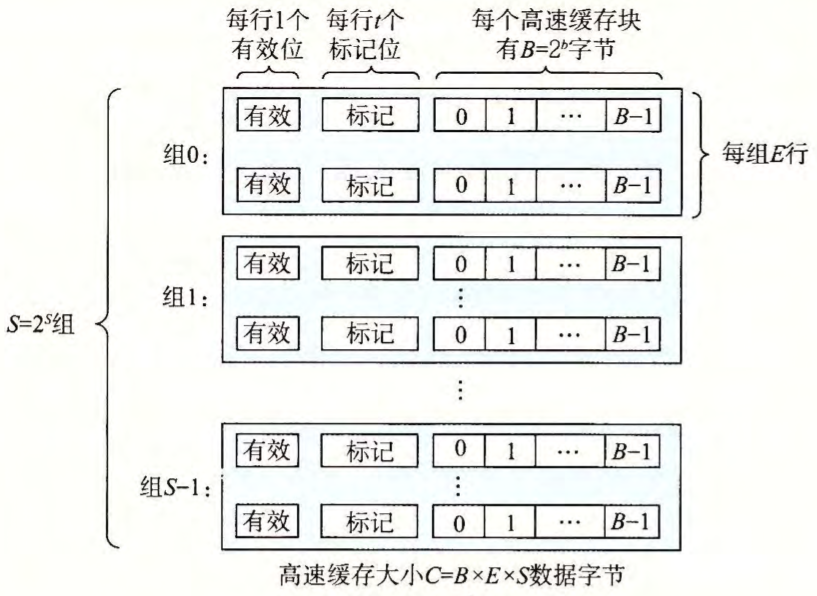
每个存储器地址有 $m$ 位,形成 $M=2^m$ 个不同的地址。高速缓存的结构将 $m$ 个地址位划分成了 $t$ 个标记位、 $s$ 个组索引位和 $b$ 个块偏移位:
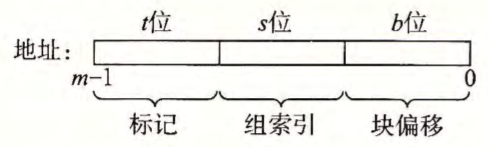
一般而言,高速缓存的结构可以用元组 $(S,\space E,\space B,\space m)$ 来描述。高速缓存的大小(或容量)$C$ 指的是所有块的大小的和。标记位和有效位不包括在内。因此, $C = S \times E \times B$ 。
高速缓存的读取方法
当一条加载指令指示 CPU 从主存地址 A 中读一个字时,它将地址 A 发送到高速缓 存。如果高速缓存正保存着地址 A 处那个字的副本,它就立即将那个字发回给 CPU。
那么高速缓存如何知道它是否包含地址 A 处那个字的副本的呢?
参数 $S$ 和 $B$ 将 $m$ 个地址位分为了三个字段。
地址 A 中的 $s$ 个组索引位是一个到 $S$ 个组的数组的索引。第一个组是组 $0$,第二个组是组 $1$,依此类推。组索引位被解释为一个无符号整数,它告诉我们这个字必须存储在哪个组中。
一旦我们知道了这个字必须放在哪个组中, A 中的 $t$ 个标记位就告诉我们这个组中的哪一行包含这个字(如果有的话)。当且仅当设置了有效位并且该行的标记位与地址 A 中的标记位相匹配时,组中的这一行才包含这个字。
一旦我们在由组索引标识的组中定位了由标号所标识的行,那么 $b$ 个块偏移位给出了在 $B$ 个字节的数据块中的字偏移。
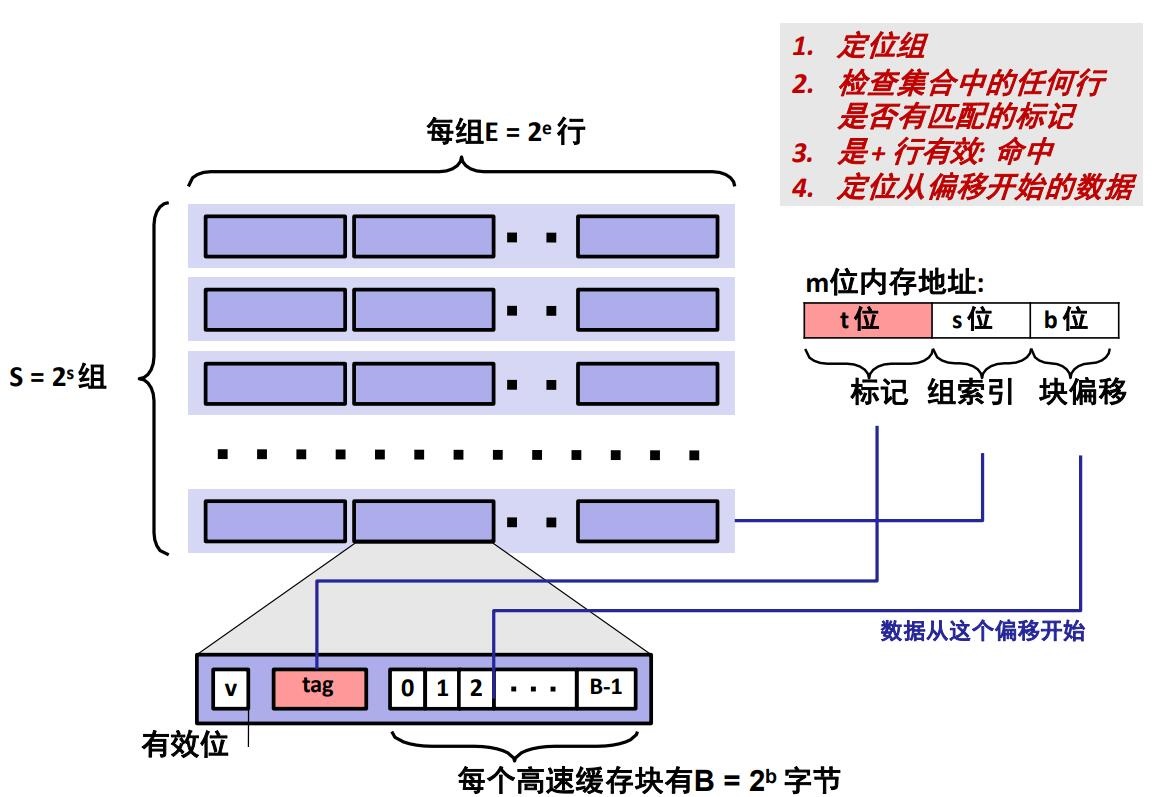
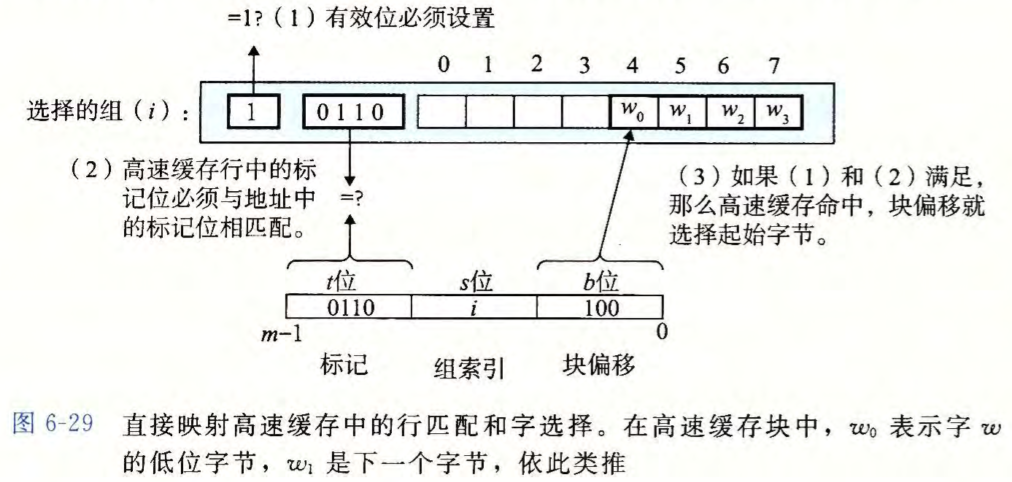
直接映射高速缓存
$E=1$。即每个组只有一行。
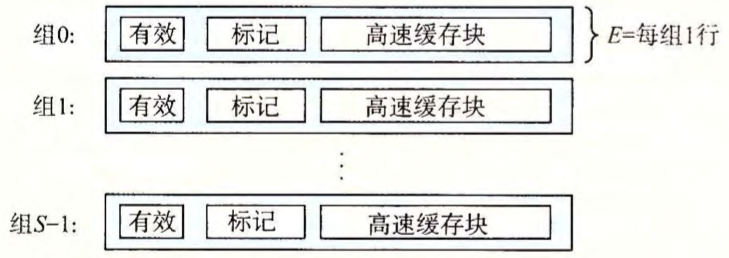
抽取被请求的字的过程
组选择
高速缓存从 $w$ 的地址中间抽取出 $s$ 个组索引位。这些位被解释成一个对应于一个组号的无符号整数 。换句话来说,如果我们把高速缓存看成是一个关于组的一维数组,那么这些组索引位就是一个到这个数组的索引 。
在下图中,组索引位 $00001_2$ 被解释为一个选择组 $1$ 的整数索引。
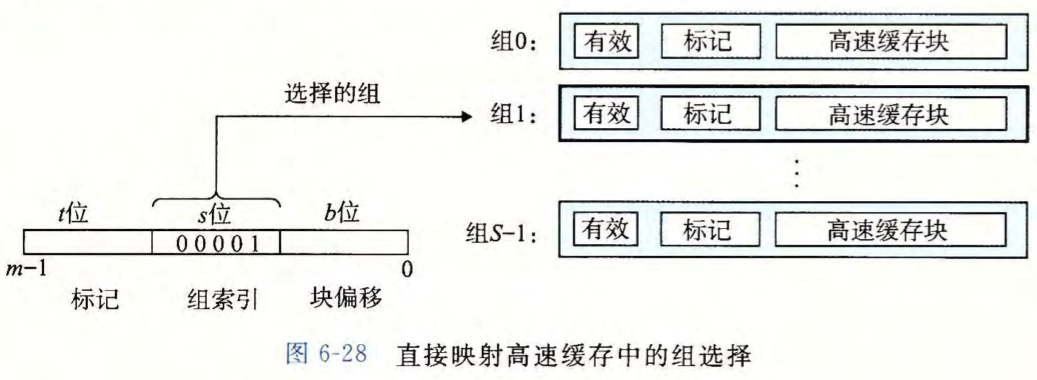
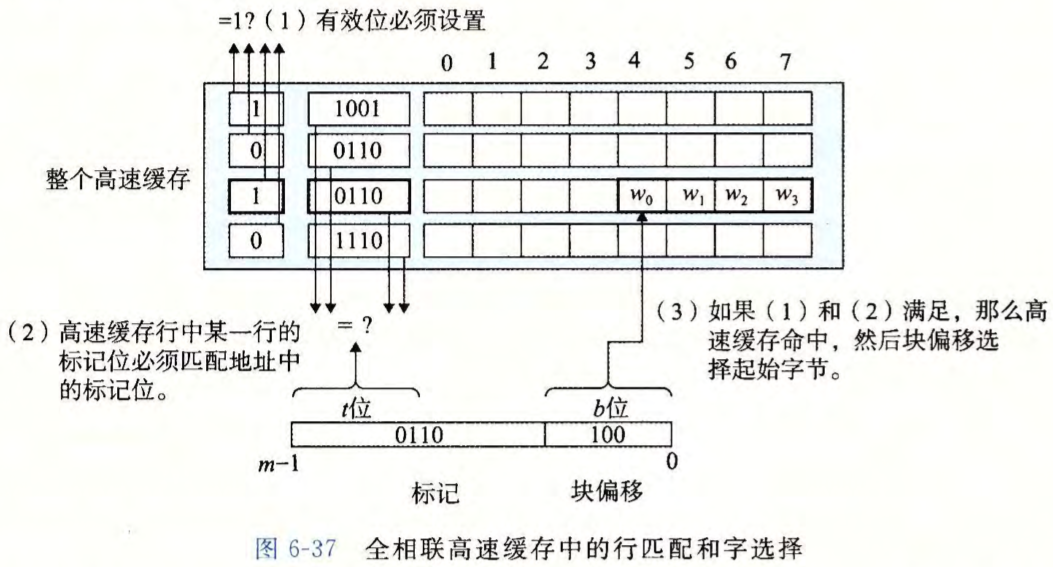
行匹配
在上一步中我们已经选择了某个组 $i$ 接下来的一步就要确定是否有字 $w$ 的一个副本存储在组 $1$ 包含的一个高速缓存行中。
因为每个组只有一行。所以当且仅当设置了有效位,而且高速缓存行中的标记与 $w$ 的地址中的标记相匹配时,这一行中包含 $w$ 的一个副本。
字选择
一旦命中,我们知道 $w$ 就在这个块中的某个地方。块偏移位提供了所需要的字的第一个字节的偏移。
在下图中,块偏移位是 $100_2$ 它表明 $w$ 的副本是从块中的字节 $4$ 开始的(我们假设字长为 4 字节)。
缓存不命中时的行替换
如果缓存不命中,那么它需要从存储器层次结构中的下一层取出被请求的块 ,然后将新的块存储在组索引位指示的组中的一个高速缓存行中。
一般而言,如果组中都是有效高速缓存行了,那么必须要驱逐出一个现存的行 。
对于直接映射高速缓存来说,每个组只包含有一行,替换策略非常简单:用新取出的行替换当前的行。
直接映射高速缓存的优点
- 硬件简单
- 成本低
- 地址变换速度快
直接映射高速缓存的缺点
- 每个主存块只有一个固定的行位置可存放。两个块映射到同一 Cache 行时就会发生冲突。发生冲突会导致频繁的置换,使 Cache 效率下降。
组相联高速缓存
满足 $1 < E < C/B$ 时,我们可以称该 cache 为 $E$ 路组相联高速缓存。
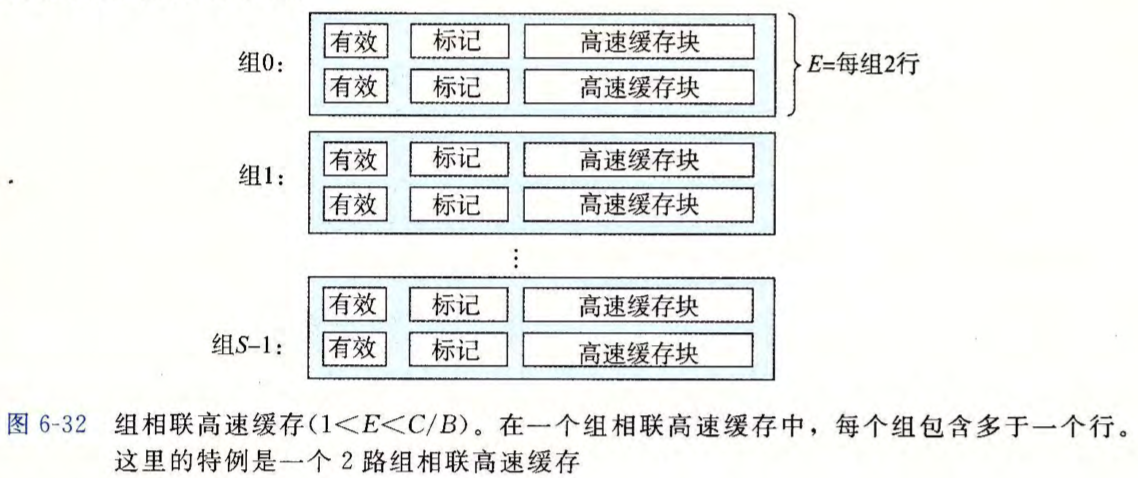
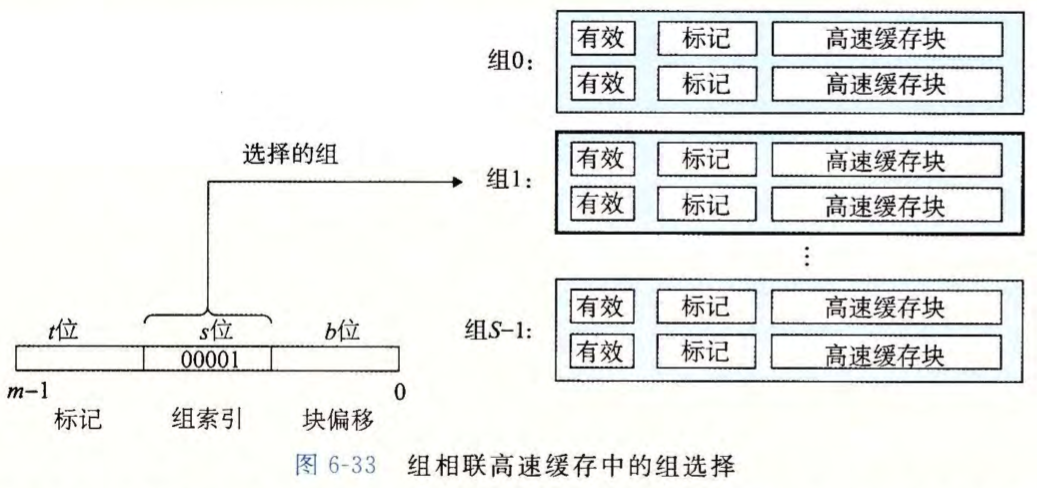
组选择
它的组选择与直接映射高速缓存的组选择一样,组索引位标识组。
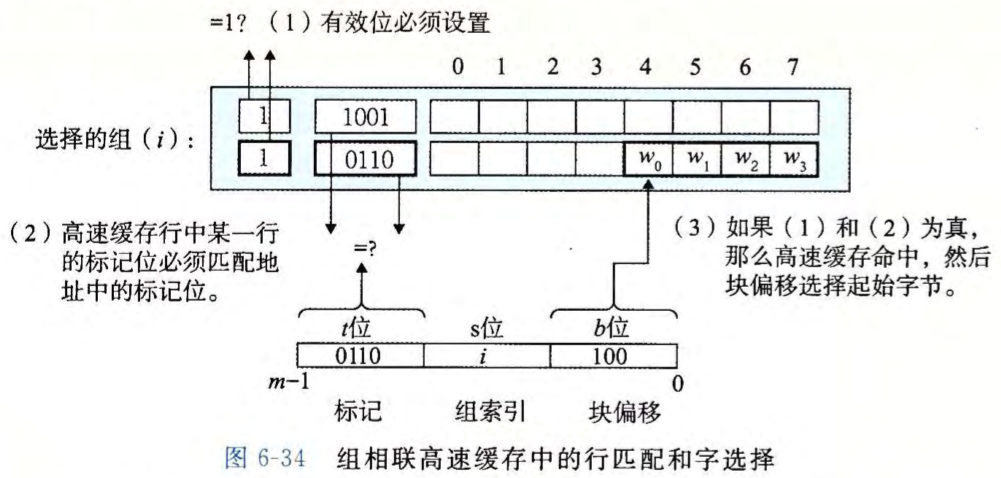
行匹配和字选择
缓存不命中时的行替换
如果 CPU 请求的字不在组的任何一行中,那么就是缓存不命中,高速缓存必须从内存中取出包含这个字的块。不过,一旦高速缓存取出了这个块,该替换哪个行呢?
最简单的替换策略是随机选择要替换的行。其他更复杂的策略利用了局部性原理,以使在比较近的将来引用被替换的行的概率最小。例如:
- 最不常使用(Least-Frequently-Used, LFU)策略会替换在过去某个时间窗口内引用次数最少的那一行。
- 最近最少使用(Least Recently-Used, LRU)策略会替换最后一次访问时间最久远的那一行。
所有这些策略都需要额外的时间和硬件。
组相联高速缓存的特点
- 灵活性:比直接映射灵活(主存可映射到组内任一块)。
- 快速性:比较次数少,只需组内全部比较,电路也较易于实现。
全相联高速缓存
当 $E=C/B$ 时,称为全相联高速缓存。
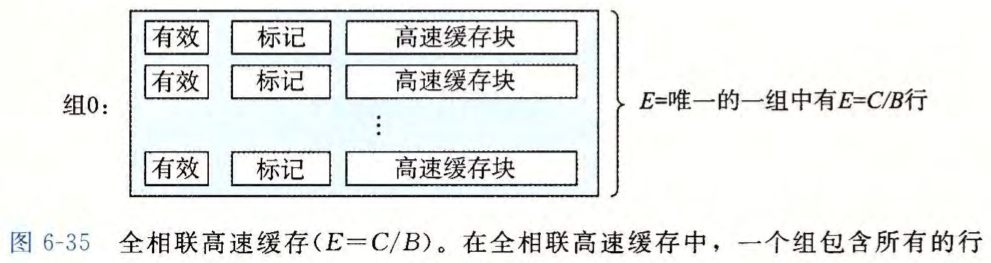
组选择
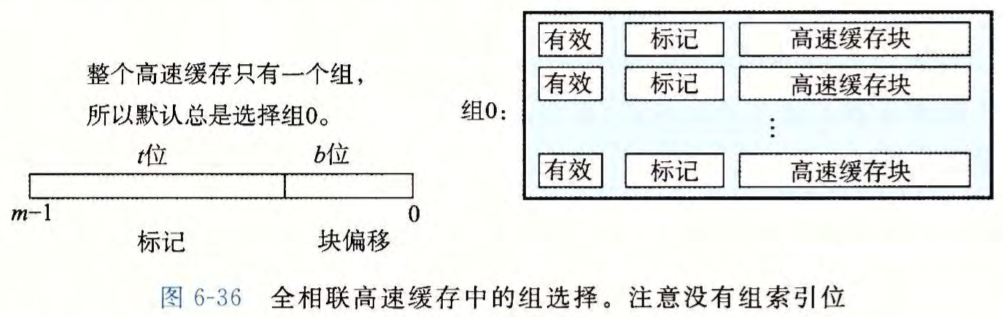
全相联高速缓存中的组选择非常简单,因为只有一个组。注意地址中没有组索引位,地址只被划分成了一个标记和一个块偏移。
行匹配和字选择
全相联映射的优点
灵活性好(最理想)
Cache 中只要有空行,就可以调入所需要的主存数据块。
全相联映射的缺点
成本高
标记位较长,使 cache 标记容量变大。
速度慢
访问 cache 时,需将所有标记比较一遍,才能最后判出所需主存中的字块是否在 cache 中。