CSAPP3e-学习笔记-第五章
CPE
引入度量标准每元素的周期数($Cycles \space Per \space Element$,$CPE$),作为一种表示程序性能并指导我们改进代码的方法。
CPE这种度量标准帮助我们在更细节的级别上理解迭代程序的循环性能。这样的度量标准对执行重复计算的程序来说是很适当的,例如处理图像中的像素,或是计算矩阵乘积中的元素。- 表示向量或列表操作的程序性能的方便方式
- 时钟频率为 $4 \space GHz$ 的处理器:
- 处理器时钟运行频率为每秒 $4×10^9$ 个周期。
- 每个时钟周期的时间是时钟频率的倒数($0.25$ 纳秒)。
- 用时钟周期来表示度量标准要比用纳秒表示有帮助得多,用时钟周期来表示,度量值表示的是执行了多少条指令, 而不是时钟运行得有多快。
CPE 的图像表示
$$
T = CPE \times Length + Overhead
$$
- $Length$:循环次数 $n$。
- $CPE$:直线的斜率 $Slope$。$CPE$ 数值越小,程序的性能越好。
- $Overhead$:经常的开销/费用。
- $T$:程序在该循环次数的总耗时。
下面展示了同一个程序的两种优化方式的性能图像($T=368+Slope \times n$)。
可以发现,下面的直线 $CPE$ 数值较小,其程序性能也更好。

妨碍优化的因素
- 函数调用
- 别名引用
程序优化的方法
代码移动
观察下列代码:
1 | |
将上述代码中的 for 循环进行如下优化的方式叫做代码移动:
1 | |
通过上述的操作,将 getLength() 函数提出到循环之外,由原来需要进行 length 次计算变为只需要一次计算,大大减少的计算量。
但是由于编译器无法确定 getLength() 函数是否存在副作用,所以不会在代码优化的时候主动进行该类代码移动。
循环展开
通过减少循环次数以及将数据并行处理以提高程序的性能。
理解现代处理器
利用指令级并行
- 需要理解现代处理器的设计
- 硬件可以并行执行多个指令
- 性能受数据依赖的限制
- 简单的转换可以带来显著的性能改进
- 编译器通常无法进行这些转换
- 浮点运算缺乏结合性和可分配性
整体操作
- 指令级并行:在代码级上,看上去似乎是一次执行一条指令,每条指令都包括从寄存器或内存取值,执行一个操作,并把结果存回到一个寄存器或内存位置。在实际的处理器中,是同时对多条指令求值的。
- 描述程序性能的两个下界:
- 延迟界限:一系列操作必须按照严格顺序执行,因为在下一 条指令开始之前,这条指令必须结束。主要是代码中的数据 相关限制了处理器利用指令级并行的能力。
- 吞吐量界限:刻画了处理器功能单元的原始计算能力。这个 界限是程序性能的终极限制。
超标量 Superscalar 处理器
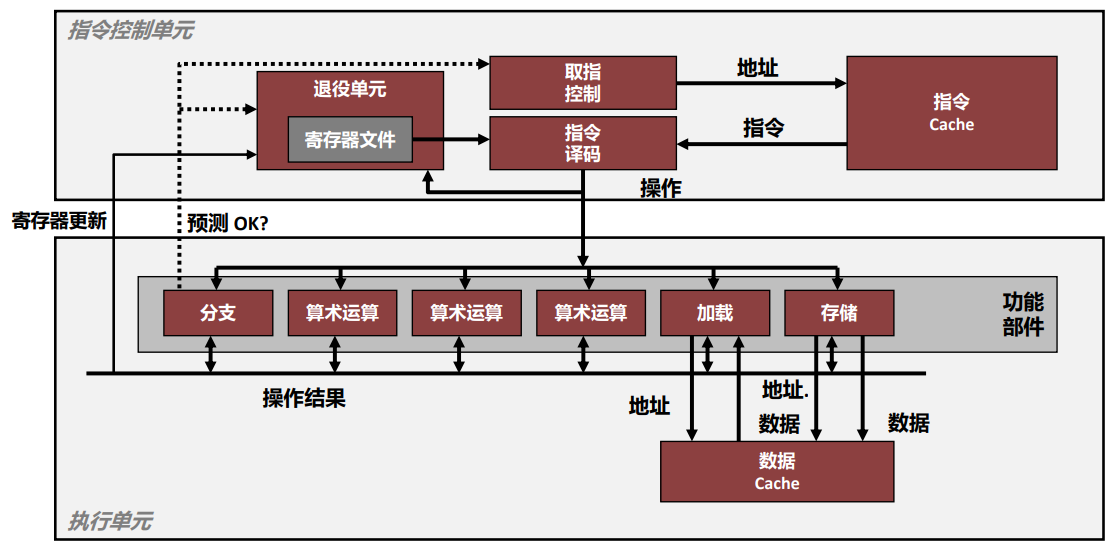
- 控制单元
ICU:从内存中读出指令序列,并根据这些指令 序列生成一组针对程序数据的基本操作 - 执行单元
EU:执行ICU产生的基本操作
功能单元
Intel Core i7 Haswell 参考机有 8 个功能单元,编号为 0~7。下面部分列出了每个单元的功能:
| 编号 | 功能 |
|---|---|
| 0 | 整数运算、浮点乘、整数和浮点数除法、分支 |
| 1 | 整数运算、浮点加、整数乘、浮点乘 |
| 2 | 加载、地址计算 |
| 3 | 加载、地址计算 |
| 4 | 存储 |
| 5 | 整数运算 |
| 6 | 整数运算、分支 |
| 7 | 存储、地址计算 |
可并行执行多条指令:
- 2 个加载,带地址计算
- 1个存储 ,带地址计算
- 4 个整数运算
- 2 个浮点乘法运算
- 1 个浮点加法
- 1 个浮点除法
功能单元的性能
延迟:表示完成运算所需要的总时间。表明执行实际运算所需要的时钟周期总数
发射时间:表示两个连续的同类型的运算之间需要的最小时间。表明两次运算之间间隔的最小周期数
容量:表示能够执行该运算的功能单元的数量。表明同时能发射多少个这样的操作
最大吞吐量:定义为发射时间的倒数
延迟界限:给出了任何必须按照严格顺序完成合并运算的函数所需的最小 CPE 值
吞吐量界限:给出了 CPE 的最小界限
优化中的限制因素
寄存器溢出
x86-64 有 16 个寄存器,16 个 ymm 寄存器保存浮点数。
当并行数量大于 16 时,部分数据将存入栈中,此时每次操作数据便会额外从栈中读取数据以及向栈中存入数据。程序整体性能将会减弱。
应用:性能提高的技术
- 高级设计:避免使用那些会渐进地产生糟糕性能的算法或编码技术。
- 基本编码原则:避免限制优化的因素,这样编译器就能产生 高效的代码。
- 消除连续的函数调用。在可能时,将计算移到循环外。考虑有选择 地妥协程序的模块性以获得更大的效率。
- 消除不必要的内存引用。引人临时变量来保存中间结果。只有在最 后的值计算出来时,才将结果存放到数组或全局变量中。
- 低级优化
- 展开循环,降低开销,并且使得进一步的优化成为可能。
- 通过使用例如多个累积变量和重新结合等技术,找到方法提高指令级并行。
- 用功能性的风格重写条件操作,使得编译采用条件数据传送
习题整理
2
3
4
5
6
7
8
9// 1
{
*xp += *yp;
*xp += *yp;
}
// 2
{
*xp += 2 * (*yp);
}无论何种情况下,以上两个代码块行为相同( B )
A. 对
B. 错
当 xp 和 yp 同时指向同一个地址时,第一个代码块的结果为 4(*xp),而第二个代码块的结果为 3(*xp)。
f1和f2是两个浮点数,关于下面两条语句,说法正确的是( D )
2f1 = (f1 + f2) + f2; // 第一条
f1 = f1 + (f2 + f2); // 第二条A. 第一条执行时间快
B. 第二条执行时间快
C. 两条语句执行结果相同
D. 两条语句执行结果可能不同
具体内容可重新查看《深入理解计算机系统》第一、二章内容。
关于现代微处理器,下面描述正确的是( A B C D )
A. 可以在每个时钟周期执行多个操作。
B. 指令执行的顺序不一定要与他们在机器级程序中的顺序一致。
C. 指令控制单元负责从内存中读出指令序列,并据其生成一组针对程序数据的基本操作。
D. 执行单元执行指令控制单元生成的操作。
《深入理解计算机系统》5.7 理解现代处理器:
现代微处理器取得的了不起的功绩之一是:它们采用复杂而奇异的微处理器结构,其中,多条指令可以并行地执行,同时又呈现出一种简单的顺序执行指令的表象。
这些处理器在工业界称为超标量 (superscalar) , 意思是 它可以在每个时钟周期执行多个操作,而且是乱序的 (out-of-order) , 意思就是指令执行的顺序不一定要与它们在机器级程序中的顺序一致。
整个设计有两个主要部分:指令控制单元 (Instruction Control Unit, ICU) 和 执行单元 (Execution Unit, EU) 。前者负责从内存中读出指令序列,并根据这些指令序列生成一组针对程序数据的基本操作;而后者执行这些操作。
下列说法正确的是( A B D )
A. 现代处理器有专门的功能单元来执行加载和存储操作。
B. 对于寄存器操作,在指令被译码成操作的时候,处理器就可以确定哪些指令会影响其他哪些指令。
C. 对于内存操作,在指令被译码成操作的时候,处理器就可以确定哪些指令会影响其他哪些指令。
D. 对于内存操作,只有到加载和存储的地址被计算出来以后,处理器才能确定哪些指令会影响其他哪些指令。
5.7 理解现代处理器:
Intel Core i7 Haswell 参考机有 8 个功能单元,编号为 0~7。下面部分列出了每个单元的功能:
编号 功能 0 整数运算、浮点乘、整数和浮点数除法、分支 1 整数运算、浮点加、整数乘、浮点乘 2 加载、地址计算 3 加载、地址计算 4 存储 5 整数运算 6 整数运算、分支 7 存储、地址计算 5.12.2 存储的性能
对于 寄存器操作,在指令被译码成操作的时候,处理器就可以确定哪些指令会影响其他哪些指令。
另一方面,对于 内存操作,只有到计算出加载和存储的地址被计算出来以后,处理器才能确定哪些指令会影响其他的哪些。
编写高效程序,下列说法正确的是( A C )
A. 程序员必须选择一组适当的算法和数据结构。
B. 大多数编译器会优化程序员给出的算法和数据结构。
C. 程序员必须编写出编译器能够有效优化以转换成高效可执行代码的源代码。
D. 大多数编译器可以轻易优化 C 语言的指针运算。
《深入理解计算机系统》第五章 优化程序性能:
编写高效程序需要做到以下几点:第一,我们必须选择一组适当的算法和数据结构。第二,我们必须编写出编译器能够有效优化以转换成高效可执行代码的源代码。C 语言的有些特性,例如执行指针运算和强制类型转换的能力,使得编译器很难对它进行优化。
优化编译器会试着进行代码移动。不幸的是,就像前面讨论过的那样,对于会改变在哪里调用函数或调用多少次的变换,编译器通常会非常小心。它们不能可靠地发现一个函数是否会有副作用,因而假设函数会有副作用,并保持所有的函数调用不变。