汇编语言:基于x86处理器-学习笔记-第三章
第三章学习笔记
汇编语言部分基本语言元素
《汇编语言:基于x86处理器(原书第7版)》 Page 42
整数常量
以字母开头的十六进制数必须加个前置0,以防汇编器将其解释为标识符。
字符串常量
和字符常量以整数形式存放一样,字符串常量在内存中的保存形式为整数字节数值序列。
例如,字符串常量 “ABCD” 就包含四个字节 41h、42h、43h、44h。
伪指令
伪指令 (directive) 是嵌入源代码中的命令,由汇编器识别和执行。
伪指令不在运行时执行,但是它们可以定义变量、宏和子程序;为内存段分配名称,执行许多其他与汇编器相关的日常任务。
默认情况下,伪指令不区分大小写。例如,.data,.DATA 和 .Data 是相同的。
定义段
汇编器伪指令的一个重要功能是定义程序区段,也称为段 (segment)。程序中的段具有不同的作用。
数据段:
.DATA伪指令表示的数据段可以用于定义变量。代码段:
.CODE伪指令标识的程序区段包含了可执行的指令。堆栈段:
.STACK伪指令标识的程序区段定义了运行时堆栈,并设置了其大小。
指令
指令 (instruction) 是一种语句,它在程序汇编编译时变得可执行。汇编器将指令翻译为机器语言字节,并且在运行时由 CPU 加载和执行。一条指令有四个组成部分:
- 标号(可选):是一种标识符,是指令和数据的位置标记。标号有两种类型:数据标号和代码标号。
- 指令助记符(必需)
- 操作数(通常是必需的)
- 注释(可选)
习题整理
计算机的
CPU每执行一个 ( ),就完成一步基本运算。 (D)
A. 软件
B. 算法
C. 程序
D. 指令
解析见上文整理内容。
在 x86 汇编语言中,汇编程序常用的三个段,分别是(代码段)、(数据段)和(堆栈段);
对于 32位 CPU,用于在循环中控制循环次数的寄存器是($ECX$),包含下一跳将要执行指令的地址的寄存器是($EIP$)。
解析见上文整理内容。
一条指令有四个组成部分,分别是标号、(指令助记符)、(操作数)和(注释)。其中,标号可分为(数据标号)和(代码标号)。
解析见上文整理内容。
程序模板
《汇编语言:基于x86处理器(原书第7版)》 Page 47, 52, 67
汇编语言程序有一个简单的结构,并且变化很小。当开始编写一个新程序时,可以从一个空 shell 程序开始,里面有所有基本的元素。通过填写缺省部分,并在新名字下保存该文件就可以避免键入多余的内容。关键字大小写均可:

汇编、连接和运行程序
《汇编语言:基于x86处理器(原书第7版)》 Page 53
用汇编语言编写的源程序不能直接在其目标计算机上执行,必须通过翻译或汇编将其转换为可执行代码。汇编器生成包含机器语言的文件,称为目标文件 (object file)。
这个文件还没有准备好执行,它还需传递给一个被称为链接器 (linker) 的程序,从而生成可执行文件 (executable file)。
这个文件就准备好在操作系统命令提示符下执行。
汇编-连接-执行周期
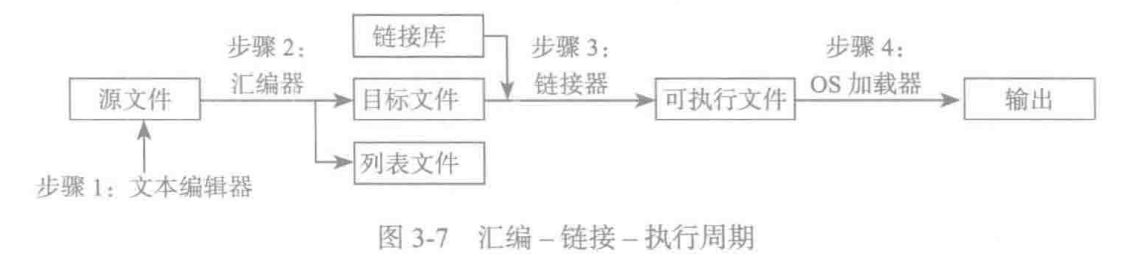
对上图每一个步骤进行说明:
- 编程者用文本编辑器 (text editor) 创建一个
ASCII文本文件,称之为源文件。 - 汇编器读取源文件,并生成目标文件,即对程序的机器语言翻译。或者,它也会生成列表文件。只要出现任何错误,编程者就必须返回步骤1,修改程序。
- 链接器读取并检查目标文件,以便发现该程序是否包含了任何对链接库中过程的调用。链接器从链接库中复制任何被请求的过程,将它们与目标文件组合,以生成可执行文件。
- 操作系统加载程序将可执行文件读入内存,并使 CPU 分支到该程序起始地址,然后程序开始执行。
习题整理
在汇编语言中,能将目标文件生成可执行文件的程序是: (C)
A. 调试程序
B. 汇编程序
C. 链接程序
D. 编译程序
链接器从链接库中复制任何被请求的过程,将它们与目标文件组合,以生成可执行文件。
定义数据
《汇编语言:基于x86处理器(原书第7版)》 Page 55
数据定义语句形如:count DWORD 12345。
内部数据类型


初始值
定义整数类型
初始值数据定义中至少要有一个初始值,即使该值为 0。
其他初始值,如果有的话,用逗号分隔(例如初始化数组:list BYTE 10, 20, 30)。对整数数据类型而言,初始值 (initializer) 是整数常量或是与变量类型,如 BTYE 或 WORD 相匹配的整数表达式。
如果程序员希望不对变量进行初始化(随机分配数值),可以用符号 ? 作为初始值。使用 ? 初始值使得变量未初始化,这意味着在运行时分配数值到该变量。
所有初始值,不论其格式,都由汇编器转换为二进制数据。初始值 00110010b、32h 和 50d 都具有相同的二进制数值。
定义字符串
定义一个字符串,要用单引号或双引号将其括起来。
最常见的字符串类型是用一个空字节(值为 0)作为结束标记,称为以空字节结束的字符串。
1 | |
十六进制代码 ODh 和 0Ah 也被称为 CR/LF (回车换行符) 或行结束字符。在编写标准输出时,它们将光标移动到当前行的下一行的左侧。
DUP 操作符
DUP 操作符使用一个整数表达式作为计数器,为多个数据项分配存储空间。在为字符串或数组分配存储空间时,这个操作符非常有用,它可以使用初始化或非初始化数据:
1 | |
定义浮点类型
REAL4 定义 4 字节单精度浮点变量。
REAL8 定义 8 字节双精度数值。
REAL10 定义 10 字节扩展精度数值。
每个伪指令都需要一个或多个实常数初始值:
1 | |
下图描述了标准实数类型的最少有效数字个数和近似范围:

习题整理
语句“array WORD 6 DUP (4)”分配主存的存储单元个数是:(B)
A. 6
B. 12
C. 24
D. 48
参考文章:吐血整理!这篇带你彻底理解主存中存储单元地址的分配 - 知乎 (zhihu.com)
通常都是以8位二进制为一个存储单元,也就是一个字节。一个 WORD 拥有2个字节,DUP 前面的数字为6,表示共创建6个 WORD,即共12个字节。
语句“array WORD 10 DUP (?)”分配主存的存储单元个数是:(20)
解析无
语句“array DWORD 10,20,30,40”分配主存的存储单元个数是:(16)
解析无
语句“array WORD 10,20,30,40”分配主存的存储单元个数是:(8)
解析无
语句“array DWORD 10,20,30,40,50”分配主存的存储单元个数是:(20)
解析无
语句“array word 5 dup(1, 2)”分配主存的存储单元个数是:(10)
待添加注释
下列哪个数据伪指令定义32位无符号整数变量:(D)
A. WORD
B. SWORD
C. BYTE
D. DWORD
WORD 16位无符号整数;SWORD 16位有符号整数;BYTE 8位无符号整数;DWORD 32位无符号整数。
下列哪个数据伪指令定义16位有符号整数变量:(B)
A. WORD
B. SWORD
C. BYTE
D. SBYTE
WORD 16位无符号整数;SWORD 16位有符号整数;BYTE 8位无符号整数;SBYTE 8位有符号整数。
下列哪个数据伪指令定义16位无符号整数变量?(C)
A. DWORD
B. SWORD
C. WORD
D. SDWORD
解析无
下列哪个数据伪指令定义32位有符号整数变量?(D)
A. DWORD
B. SWORD
C. FWORD
D. SDWORD
解析无
下列哪个数据伪指令定义8位有符号整数变量?(SBYTE)
解析无
小端顺序
《汇编语言:基于x86处理器(原书第7版)》 Page 62
x86 处理器在内存中按小端顺序 (低到高) 存放和检索数据。
最低有效字节存放在分配给该数据的第一个内存地址中,剩余字节存放在随后的连续内存位置中。
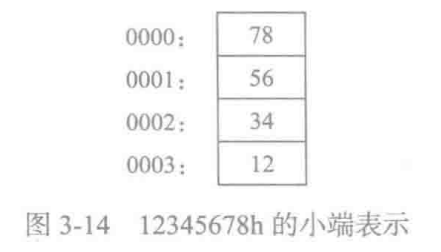
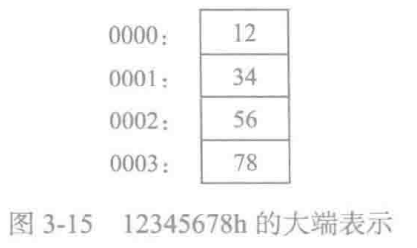
其他有些计算机系统采用的是大端顺序(高到低)。下图展示了 12345678h 从偏移量 0000 开始的大端顺序存放。
习题整理
变量保存于字节编址的内存存储器中,每个存储单元保存一个8位、字节量数据。多个字节数据顺序逐个存放在主存相邻单元。
一般采用小端方式存储,即高字节数据保存在(高地址)存储单元,低字节数据保存在(低地址)存储单元。
解析见上文整理内容。
符号常量
《汇编语言:基于x86处理器(原书第7版)》 Page 63
等号伪指令
1 | |
通常,表达式是一个32位的整数值。当程序进行汇编时,在汇编器预处理阶段,所有出现的 name 都会被替换为 expression。类比 C 语言的 #define name expression。
计算数组大小
$ 运算符(当前地址计数器)返回当前程序语句的偏移量。在下例中,从当前地址计数器($)中减去list的偏移量,计算得到 ListSize。ListSize 必须紧跟在 list 的后面。
1 | |
字数组和双字数组
当要计算元素数量的数组中包含的不是字节时,就应该用数组总的大小(按字节计)除以单个元素的大小。
比如,在下例中,由于数组中的每个字要占2个字节(16位),因此,地址范围应该除以2:
1 | |
同样,双字数组中每个元素长4个字节,因此,其总长度除以4才能产生数组元素的个数:
1 | |